- 700+ observations
- ~50 changes implemented
- 9 agents in study
- 4 weeks end-to-end
- Role
- Study design, moderation, analysis
- Team
- Research team (2), Mobee Dick
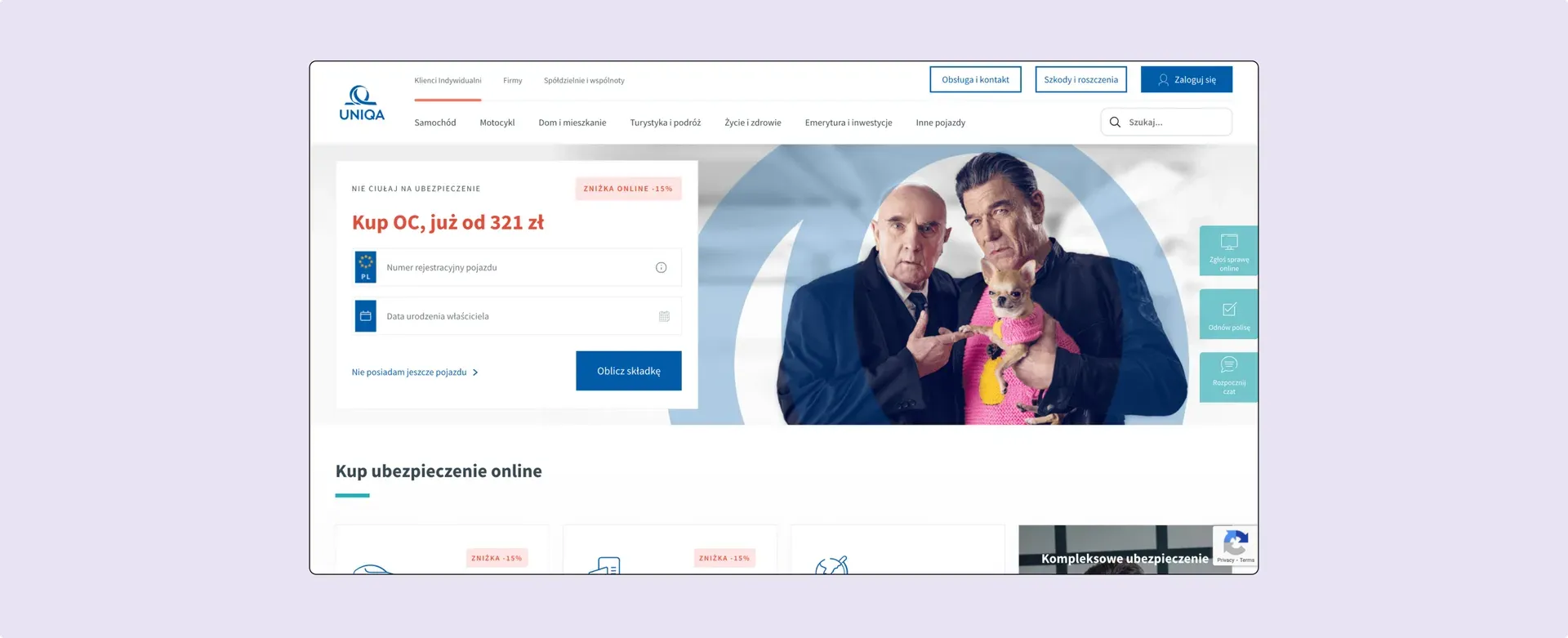
Usability testing of a new portal for UNIQA’s insurance agents, run as RITE — with debriefs after each batch of sessions and fixes shipped to the prototype before the next participant sat down.
Early 2022. The UNIQA team was preparing to roll out a new version of their portal for insurance agents and — before pushing it to production — wanted to check whether it would actually hold up in daily use.
At the start of the project, we broke down the general study goal — verifying the prototype’s usability — into more specific areas:
Checking how users understand content, messages, and terminology on individual screens.
Understanding how users perceive the categorisation of insurance products.
Analysing how users search for specific products, policies, and offers.
Testing the usability of calculator shortcuts and quick action features.
Evaluating alternative versions of the homepage.
A prototype, a rollout pushed further down the road, and a client team that wanted to be part of the process — these conditions made the choice almost pick itself: RITE (Rapid Iterative Testing and Evaluation).
RITE shortens the path from observation to fix, but it comes with a pitfall: changes made mid-study make it harder to compare what each participant actually experienced. To keep those decisions deliberate rather than reflexive, we sorted observations into categories — what gets fixed right away, what goes into a queue outside the study timeline, what we keep observing, and what stems from external context and may not require a prototype change at all. Every change was documented and tied to the session from which it went live. Decisions were made together, during team debriefs.
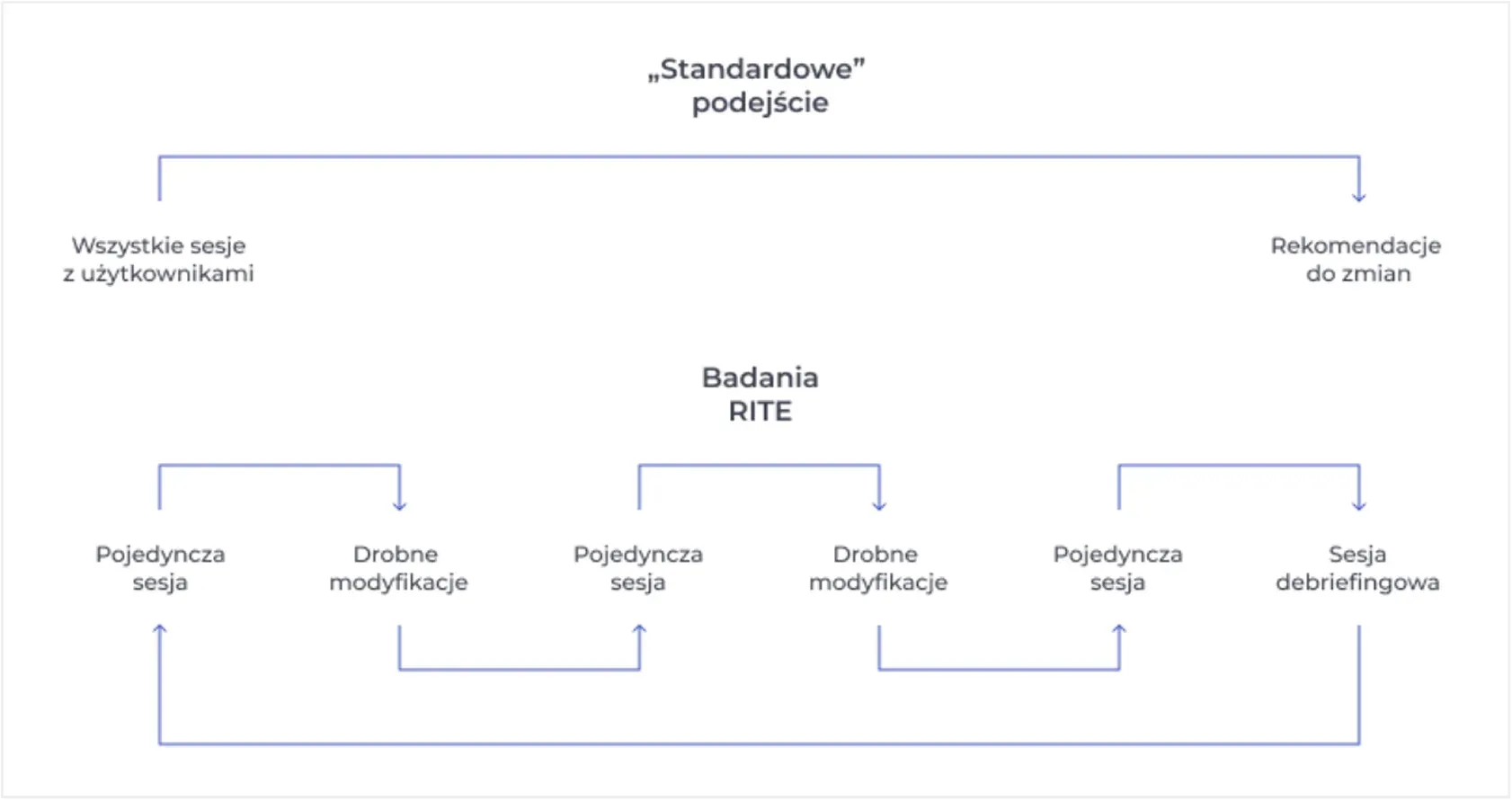
RITE research formula
Sample
9 insurance agents. Too few for statistical testing, more than you’d use for pure exploration — but about right for RITE. You give up sample size and get density of observations per participant, plus the ability to check whether each fix actually solves the problem. Recruitment criteria were set jointly with the client.
Pilot session
Before the first participant came in, we ran the full scenario end to end as a dry run. That let us adjust the order of tasks, rephrase a few probing questions, and iron out the logistics of running it online — screen sharing, splitting the moderator and observer roles.
With clearly defined research goals and access to a working prototype, I prepared a usability test script that standardised the flow of sessions with participants.
Sample tasks and probing questions
Task 1
“A client comes to your office wanting to buy life insurance for themselves and their family. Using the portal, present an offer tailored to their needs.”
Follow-up questions
Task 2
“You receive a phone call from your regional manager informing you that some clients are behind on their policy payments. Try to resolve this issue.”
Follow-up questions
During the project, I served as both moderator and observer of the research sessions. We documented observations on a FigJam interactive whiteboard, and conducted sessions remotely using MS Teams.
One of the research sessions moderated by the author
Observation space on the FigJam interactive whiteboard
Debriefs were the core of the process. We met every 2–4 sessions — or after just one, if something called for a quick decision. Together we walked through the script: what each of us noticed, what it meant, what to do about it.
Observations lived on FigJam — one sticky per note, each caught by a team member during the session or on replay afterward. By the end of the study there were around 700 of them. At debriefs we first grouped them bottom-up, looking for what repeated, and then mapped them against research goals G01–G05. Observations that landed in more than one category were the strongest signals for us.
After each debrief we documented the decisions — including smaller changes made between sessions. That gave us a change log we could reach for at any point, so we always knew where a given solution came from.

Categorization of observations including themes and minor threads
Sample summary of a debriefing session
Around 50 changes made it into the product — from naming and microcopy tweaks, through reconfiguring elements on specific screens, all the way to picking one of the tested homepage versions. After each round of sessions the prototype walked into the client meeting not as a list of problems, but as a list of decisions to make.
Out of five original research goals, we answered four. The fifth — the architecture of product categories — turned out to run deeper than we’d assumed. Rather than force a rushed answer, we made it the starting point for a separate recommendation.
RITE is a completely different working rhythm than two classic testing rounds. After research sessions, we met with the client almost immediately to discuss observations and plan iterations. Fixes made it into the prototype before the next test. That intensity demanded fast decision-making, but it offered something the traditional model doesn't: the ability to verify a fix with the very next participant.
An equally important lesson was managing the client relationship. Involving the UNIQA team in the process – inviting them to sessions, running joint debriefs, preparing materials on observation best practices – built trust and shared ownership of the results. At the same time, I learned that taking care of a client isn't just keeping them in the loop, but also setting clear boundaries: for instance, on when a prototype change is ready for testing and when it needs more work.
I would propose running card sorting before the usability tests. One of the key findings was that agents disagreed on how insurance products should be categorised – a problem that usability testing can reveal but not solve. Had we investigated the information architecture earlier, we could have spent the sessions testing interactions rather than discovering that the content structure itself needed rethinking.